Adversarial Counterfactual Visual Explanations
Abstract
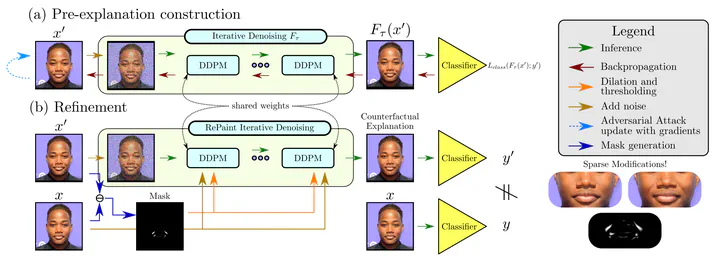
Counterfactual explanations and adversarial attacks have a related goal- flipping output labels with minimal perturbations regardless of their characteristics. Yet, adversarial attacks cannot be used directly in a counterfactual explanation perspective, as such perturbations are perceived as noise and not as actionable and understandable image modifications. Building on the robust learning literature, this paper proposes an elegant method to turn adversarial attacks into semantically meaningful perturbations, without modifying the classifiers to explain. The proposed approach hypothesizes that Denoising Diffusion Probabilistic Models are excellent regularizers for avoiding highfrequency and out-of-distribution perturbations when generating adversarial attacks. The paper’s key idea is to build attacks through a diffusion model to polish them. This allows studying the target model regardless of its robustification level. Extensive experimentation shows the advantages of our counterfactual explanation approach over current State-of-the-Art in multiple testbeds.
Date
Apr 2, 2024 3:00 PM — 3:40 PM
Event
EMIL Spring'24 Seminars
Location
Health Futures Center, ASU