LEAD: Localized Explanations with Adversarial Decision Boundary Characterization for Interpretable Disease Prediction
Abstract
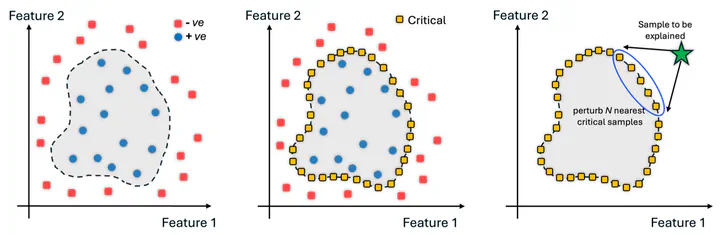
Understanding the reasoning behind a model’s decision-making process is highly sought after in safety-critical domains like digital health where predicting the onset of a disease or occurrent of an adverse outcome if desirable. Gaining insights into what drives a model to a specific decision enhances interpretability, trust, and acceptance. Furthermore, model’s decision making process helps end-users (i.e., patients, caregivers, clinicians) make appropriate decisions to prevent an impending adverse clinical outcome. This paper introduces LEAD, a novel method for generating localized feature explanations by perturbing adversarial critical samples near the sample to be explained. By focusing on neighboring critical samples along the decision boundary—rather than on the test sample directly—LEAD reduces the impact of noise or irrelevant features on feature importance estimation. Additionally, leveraging these borderline instances enhances robustness against adversarial attacks. Our extensive experiments on two datasets with physiological signal sensing features showcase the effectiveness of LEAD with at least 6% improved fidelity, 7% improved consistency, high sparsity, and competitive robustness, compared to those of the competing explainable AI techniques.
Type
Publication
The 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), July 14–17, 2025, Copenhagen, Denmark